
REINFORCE js
# About
**REINFORCEjs** は強化学習ライブラリです。REINFORCEjs はウェブのデモで強化学習の有名なアルゴリズムをサポートしています。
[カルパシー @karpathy](https://twitter.com/karpathy) によってメンテナンスされています。現在は以下が含まれます。
### ダイナミックプログラミング Dynamic Programming
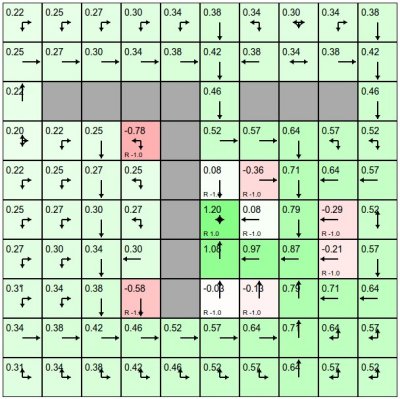
(あまり大きすぎない) 有限決定論的マルコフ決定過程 MDP を解くためのソルバーです。
ソルバーは標準的な表形式のメソッドを使用します。
警告ベルや警笛は存在せず,ダイナミクスは環境によって与えられます。
### 表形式の TD 学習
SARSA と Q-学習 の両方が含まれています。
エージェントは表形式の値関数で動作します。ですが,環境モデルを必要としません。すなわちエージェントは経験から学習します。
また Eligibility Traces や Planning (優先順位スイープ付き) など、多くの警告ベルや警笛 がサポートされています。
### 深層 Q 学習 Deep Q Learning
[Mnih et al.](http://www.nature.com/nature/journal/v518/n7540/full/nature14236.html) による Atari の
ビデオゲームを解くモデルの再実装です。
このアプローチは,ニューラルネットワークを用いて 行動値関数 Q(s,a) をモデル化してします。
表形式ではなくて,連続入力空間が可能となっています。ですが,アクションは離散的です。
この実装では ほとんどの機能が含まれています (例:経験リプレイ、頑健性のための TD エラークランプ)。
### 方策勾配法 Policy Gradients
実装には 価値のベースラインと REINFORCE と LSTM を用いた確率的方策勾配法を使った エージェント と [Silver et al](http://www0.cs.ucl.ac.uk/staff/d.silver/web/Publications_files/deterministic-policy-gradients.pdf) による最近の 決定論的方策勾配法 (deterministic Policy Gradients の実装が含まれています。 これらの多くを実現するために(特に LSTM など) このライブラリには 私の以前のプロジェクト[recurrentjs](https://github.com/karpathy/recurrentjs) の フォークが含まれています。
方策勾配法 の デモは含まれていません。ですが 現在の実装は 残念ながら(確率論的、決定論的なものの両方とも)不安定です。
誰かが詮索したい場合に備えて、 私はライブラリにコードが含まれています。
私は、バグがあるか (確かに知ることが難しいことを証明しています) あるいは、 それらを確実に動作させるために必要なヒントやコツが不足しているのではないかと疑っています。
## ライブラリの使用例
このライブラリをインクルードするには以下のようにしてください:
```javascript
```
ほとんどのアプリケーション(単純なゲームなど)では 深層 Q ネットワーク (DQN) アルゴリズムを使用するのが安全です。
プロジェクトの状態空間が有限で大きすぎない場合には 動的プログラミング (DP) や 表形式 の TD メソッド がより適切です。
例として DQN エージェント は 非常にシンプルな API を満たしています。
// create an environment object
var env = {};
env.getNumStates = function() { return 8; }
env.getMaxNumActions = function() { return 4; }
// create the DQN agent
var spec = { alpha: 0.01 } // see full options on DQN page
agent = new RL.DQNAgent(env, spec);
setInterval(function(){ // start the learning loop
var action = agent.act(s); // s is an array of length 8
//... execute action in environment and get the reward
agent.learn(reward); // the agent improves its Q,policy,model, etc. reward is a float
}, 0);