TD (時間差)学習, SARSA, 期待 SARSA, Q 学習 と Python 実装
強化学習の中心的で斬新なアイデアを一つ挙げるとすれば、それは間違いなく時間差(TD)学習であろう。
-- アンドリュー・バルト, リチャード・S・サットン
前提知識
- 強化学習の基本
- マルコフ連鎖, マルコフ決定プロセス(MDP)
- ベルマン方程式
- 価値,方策関数,反復
強化学習におけるモデル依存学習とモデル自由学習
モデル依存 RLアルゴリズム(すなわち、値と方策反復)は,遷移表の助けを借りて動作します。
遷移表は、エージェントが存在する世界で成功するために必要なすべての知識が書かれたライフハック本と考えることができます。
当然のことながら、そのような本を書くのは非常に面倒で、ほとんどの場合不可能です。
Temporal Difference はモデル自由型の強化学習アルゴリズムです。
これは、エージェントがすぐに入手可能な全知全能のハックブック(遷移表)ではなく、実際の経験を通して学習することを意味します。
これにより、確率的な要素と状態-行為ペアの大規模な系列を導入することが可能になります。
エージェントは、報酬システムと遷移システムについては何も知りません。
エージェントは、任意の状態で任意の行動をとった場合に何が起こるかを知りません。
エージェントは、「世界」や「環境」と相互作用し、自分自身で見つけ出さなければなりません。
TD 学習 (時差学習)
TD 時間差学習アルゴリズムは、エージェントが取る一つ一つの行動を通して学習することを可能にします。
TD 学習では、エピソード(ゴールや終了状態に到達する)ごとではなく、タイムステップ(行動)ごとにエージェントの知識を更新します。
上式の 目標-古い状態評価 を目標誤差と呼びます。
ステップサイズ は 通常 で表され、学習率と呼ばれます。 の値は 0 から 1 の間になります。
上式は、タイムステップごとに更新を行うことで、Target を達成するのに役立ちます。
目標とは状態の効用(関数)です。
効用が高ければ、エージェントが移行しやすい状態になることを意味します。
ここでは Bellman 方程式 を知っている と仮定しています。
ベルマン方程式から,ある状態の効用は、以下の割引報酬の期待値です。
平たく言えば、我々はエージェントを世界に自由に走らせます。
エージェントは、状態、報酬、遷移についての知識を持っていません。
エージェントは環境と相互作用し(ランダムな行動や情報に基づいた行動をとる)、すべての行動をとった後に既存の知識を継続的に更新することで、 新たな推定値(状態と行動のペアの値)を学習します。
これまでの議論では、次のようないくつかの疑問が出てきます。
エージェントはどのように環境と相互作用するのか?
エージェントはどのように行動を選択するのか、すなわち 特定の状態(ポリシー) でどのような行動をとるのか?
これが SARSA と Q-学習 の出番です。
これらは、環境の中でエージェントを誘導し、興味深いことを学ぶことを可能にする 2 つの 制御ポリシーです。
これらを説明する前に、環境とは何かを議論しなければなりません。
環境
環境は、エージェントが離散的な状態を観察し、行動をとり、その行動をとることで報酬を観察することができるミニ世界と考えることができます。
ビデオゲームは環境であり、自分自身がエージェントであると考えてください。
ゲーム「ドゥーム」では、エージェントであるあなたは、状態(画面のフレーム)を観察し、アクション(前進、後退、ジャンプ、シュートなどのキーを押す)を行い、報酬を観察します。
敵を殺せば喜び (効用) が得られ、前進している間はプラスの報酬が得られ、あまり報酬は得られませんが、将来の報酬(敵を見つけて殺す) を得るために ゲームをしたいと思うでしょう。
このような環境を作るのは面倒で大変な作業です (7人のチームが1年以上かけて Doom を開発)。
OpenAI gym が登場したことは福音です。
gym は 様々な強化学習アルゴリズムをテストできる環境が組み込まれている Python ライブラリ です。
結果を共有したり、分析したり、比較したりするための学術的な標準環境としての地位を確立しています。
Gym は ドキュメントが整備されていて、使いやすいです。
ドキュメントを読んで慣れておく必要があります。
強化学習の応用のためには、自分で環境を作る必要があります。
常に gym 互換の環境を参考にして書いて、誰もが使えるように公開しておくことをお勧めします。
Gym の ソースコードを読めば、公開ができるようになります。
面倒だけど楽しい! と思っている人にはおすすめです。
SARSA
SARSA とは,State-Action-Reward-State-Action の省略形です
SARSA とははオンポリシーな 時間差制御方式 です。
ポリシー (方策) とは 状態 と 動作(行動) とのペアのことです。
python では 状態 を キー、動作(行動) を 値 とする 辞書 dict と考えることができます。
ポリシー(方策) は各状態 で取るべき 動作(行動) をマッピングします。
オンポリシー制御では、学習中にある ポリシー (大抵はポリシー反復 のように自分自身で評価しているもの) に従うことで、 状態ごとに 動作 (行動) を選択します。
我々の目的は、現在の 方策 と全ての 状態行動 のペアについて、 を推定することです。
これは、ある 状態-動作(行動) の対 から 別の 状態-動作(行動) のペア に エージェント を遷移させることで、 タイムステップ ごとに 適用される TD 更新規則 を用いて行う (状態 から 別の 状態に エージェントを遷移させる モデル依存型 強化学習技法とは異なります)。
Q-値 状態の効用値についてはすでにお馴染みでしょうが、Q-値 も同じです。
Q-値 は、状態と行動のペアとその効用を表す実数とのマッピングです。
Q-学習 と SARSA とは、すべての 行動-状態 のペアに対して 最適な Q-値 を評価する 方策制御手法です。
SARSA の更新則は:
ある状態 が終了した場合 (ゴールに達したり,終了状態に陥った場合), となります。
ここで, は全行動レパートリーを表します。

- $Q(s,a)$ を全状態 $s$ と 全動作 $a$ について初期化,$Q(\text{終了状態},\cdot)=0$ とする
- 各エピソードを繰り返す:
- $S$ を初期化する
- $S$ の中から Q 関数に従って $A$ を選ぶ
- $Q(S,A)\leftarrow Q(S,A)+\alpha\left[R+\gamma Q(S',S')-Q(S,A)\right]$
- $S\leftarrow S'$, $A\leftarrow A'$
- $S$ が収束するまで繰り返す
イプシロン () 貪欲(欲張り) 方策
イプシロン貪欲な方策とは以下のことを言います:
- 0 から 1 の範囲 () の乱数 を一つ発生させます
- もし であれあば,ランダムにある行動を選択します
- そうでなければ (すなわち ) 値 (最大効用をあたえる) 行動を選択します
以下に Python コードを示します:
1
2
3
4
5
6
7
8
9
10
11
12 | def epsilon_greedy(Q, epsilon, n_actions, s, train=False):
"""
@param Q Q values state x action -> value
@param epsilon for exploration
@param s number of states
@param train if true then no random actions selected
"""
if train or np.random.rand() < epsilon:
action = np.argmax(Q[s, :])
else:
action = np.random.randint(0, n_actions)
return action
|
Source: https://gist.githubusercontent.com/TimeTraveller-San/40a7a2655743bf6230706d45d1201b49/raw/25ddaaf54e946d33576e27e6bab45a40f22864a9/epsilon_greedy.py
の値は 探索 = 知識利用 のジレンマ を決定します。英語では exploration-exploitatoin dilemma と呼びます。綴が似ているために英語で覚えた方が良いでしょう。
-
が大きければ、乱数 が より大きくなることはほとんどなく、 ランダムな行動はほとんど起こらない (探索が少なく、知識利用 が多くなる)。
-
が小さければ、乱数 は よりも大きくなることが多いので、 エージェント は より 多く の ランダム な 行動 を 選択 する こと に なる。
このような確率的な性質を利用して、エージェントは環境をより探索することができるようになります。
経験則として、 は通常 に選ばれます。
ですが は 環境タイプに応じて変化させることができます。
いくつかのケースでは、より高い探索に続いてより高い知識利用 を可能にするために、時間の経過とともに は 緩和 漸減 されます。
以下2 Taxi-v2 の gym 環境に適用された SARSA のシンプルな Python コードを示します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111 | import gym
import numpy as np
import time
"""
SARSA on policy learning python implementation.
This is a python implementation of the SARSA algorithm in the Sutton and Barto's book on
RL. It's called SARSA because - (state, action, reward, state, action). The only difference
between SARSA and Qlearning is that SARSA takes the next action based on the current policy
while qlearning takes the action with maximum utility of next state.
Using the simplest gym environment for brevity: https://gym.openai.com/envs/FrozenLake-v0/
"""
def init_q(s, a, type="ones"):
"""
@param s the number of states
@param a the number of actions
@param type random, ones or zeros for the initialization
"""
if type == "ones":
return np.ones((s, a))
elif type == "random":
return np.random.random((s, a))
elif type == "zeros":
return np.zeros((s, a))
def epsilon_greedy(Q, epsilon, n_actions, s, train=False):
"""
@param Q Q values state x action -> value
@param epsilon for exploration
@param s number of states
@param train if true then no random actions selected
"""
if train or np.random.rand() < epsilon:
action = np.argmax(Q[s, :])
else:
action = np.random.randint(0, n_actions)
return action
def sarsa(alpha, gamma, epsilon, episodes, max_steps, n_tests, render = False, test=False):
"""
@param alpha learning rate
@param gamma decay factor
@param epsilon for exploration
@param max_steps for max step in each episode
@param n_tests number of test episodes
"""
env = gym.make('Taxi-v2')
n_states, n_actions = env.observation_space.n, env.action_space.n
Q = init_q(n_states, n_actions, type="ones")
timestep_reward = []
for episode in range(episodes):
print(f"Episode: {episode}")
total_reward = 0
s = env.reset()
a = epsilon_greedy(Q, epsilon, n_actions, s)
t = 0
done = False
while t < max_steps:
if render:
env.render()
t += 1
s_, reward, done, info = env.step(a)
total_reward += reward
a_ = epsilon_greedy(Q, epsilon, n_actions, s_)
if done:
Q[s, a] += alpha * ( reward - Q[s, a] )
else:
Q[s, a] += alpha * ( reward + (gamma * Q[s_, a_] ) - Q[s, a] )
s, a = s_, a_
if done:
if render:
print(f"This episode took {t} timesteps and reward {total_reward}")
timestep_reward.append(total_reward)
break
if render:
print(f"Here are the Q values:\n{Q}\nTesting now:")
if test:
test_agent(Q, env, n_tests, n_actions)
return timestep_reward
def test_agent(Q, env, n_tests, n_actions, delay=0.1):
for test in range(n_tests):
print(f"Test #{test}")
s = env.reset()
done = False
epsilon = 0
total_reward = 0
while True:
time.sleep(delay)
env.render()
a = epsilon_greedy(Q, epsilon, n_actions, s, train=True)
print(f"Chose action {a} for state {s}")
s, reward, done, info = env.step(a)
total_reward += reward
if done:
print(f"Episode reward: {total_reward}")
time.sleep(1)
break
if __name__ =="__main__":
alpha = 0.4
gamma = 0.999
epsilon = 0.9
episodes = 3000
max_steps = 2500
n_tests = 20
timestep_reward = sarsa(alpha, gamma, epsilon, episodes, max_steps, n_tests)
print(timestep_reward)
|
source: https://gist.github.com/TimeTraveller-San/4aa1ed2d0644ad05d84348dd4fb797f3#file-sarsa-py
Q 学習
Q-学習 は、方策によらない TD 制御です。
SARSA とほぼ同じです。唯一の違いは、次の 動作(行動) を見つけるための 方策に従うのではなく、 貪欲に 動作(行動) を選択することです。
SARSA と同様に Q値 を評価することを目的としており、更新則 は次のようになります:
SARSA では、ある方策 に従って 行動 を選択していました。
これに対し、上式 Q 学習 では 行動 () は、 の最大値を取るだけの 欲張り(貪欲, グリーディ)な 方法で選択されます。
Q 学習のアルゴリズムを以下に示します:

Python コードは以下になります:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113 | import gym
import numpy as np
import time
"""
Qlearning is an off policy learning python implementation.
This is a python implementation of the qlearning algorithm in the Sutton and
Barto's book on RL. It's called SARSA because - (state, action, reward, state,
action). The only difference between SARSA and Qlearning is that SARSA takes the
next action based on the current policy while qlearning takes the action with
maximum utility of next state.
Using the simplest gym environment for brevity: https://gym.openai.com/envs/FrozenLake-v0/
"""
def init_q(s, a, type="ones"):
"""
@param s the number of states
@param a the number of actions
@param type random, ones or zeros for the initialization
"""
if type == "ones":
return np.ones((s, a))
elif type == "random":
return np.random.random((s, a))
elif type == "zeros":
return np.zeros((s, a))
def epsilon_greedy(Q, epsilon, n_actions, s, train=False):
"""
@param Q Q values state x action -> value
@param epsilon for exploration
@param s number of states
@param train if true then no random actions selected
"""
if train or np.random.rand() < epsilon:
action = np.argmax(Q[s, :])
else:
action = np.random.randint(0, n_actions)
return action
def qlearning(alpha, gamma, epsilon, episodes, max_steps, n_tests, render = False, test=False):
"""
@param alpha learning rate
@param gamma decay factor
@param epsilon for exploration
@param max_steps for max step in each episode
@param n_tests number of test episodes
"""
env = gym.make('Taxi-v2')
n_states, n_actions = env.observation_space.n, env.action_space.n
Q = init_q(n_states, n_actions, type="ones")
timestep_reward = []
for episode in range(episodes):
print(f"Episode: {episode}")
s = env.reset()
a = epsilon_greedy(Q, epsilon, n_actions, s)
t = 0
total_reward = 0
done = False
while t < max_steps:
if render:
env.render()
t += 1
s_, reward, done, info = env.step(a)
total_reward += reward
a_ = np.argmax(Q[s_, :])
if done:
Q[s, a] += alpha * ( reward - Q[s, a] )
else:
Q[s, a] += alpha * ( reward + (gamma * Q[s_, a_]) - Q[s, a] )
s, a = s_, a_
if done:
if render:
print(f"This episode took {t} timesteps and reward: {total_reward}")
timestep_reward.append(total_reward)
break
if render:
print(f"Here are the Q values:\n{Q}\nTesting now:")
if test:
test_agent(Q, env, n_tests, n_actions)
return timestep_reward
def test_agent(Q, env, n_tests, n_actions, delay=1):
for test in range(n_tests):
print(f"Test #{test}")
s = env.reset()
done = False
epsilon = 0
while True:
time.sleep(delay)
env.render()
a = epsilon_greedy(Q, epsilon, n_actions, s, train=True)
print(f"Chose action {a} for state {s}")
s, reward, done, info = env.step(a)
if done:
if reward > 0:
print("Reached goal!")
else:
print("Shit! dead x_x")
time.sleep(3)
break
if __name__ =="__main__":
alpha = 0.4
gamma = 0.999
epsilon = 0.9
episodes = 10000
max_steps = 2500
n_tests = 2
timestep_reward = qlearning(alpha, gamma, epsilon, episodes, max_steps, n_tests, test = True)
print(timestep_reward)
|
source: https://gist.github.com/TimeTraveller-San/9e56f9d09be7d50b795ef2f83be2ba72#file-qlearning-py
期待 SARSA
期待 SARSA とは、その名が示すように、現在の状態で起こりうるすべての行動についての Q値 の期待値(平均値)を取ります。
ターゲットの更新則を使うと、より明確になります。
Python コードを以下に示します:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115 | import gym
import numpy as np
import time
"""
SARSA on policy learning python implementation.
This is a python implementation of the SARSA algorithm in the Sutton and Barto's book on
RL. It's called SARSA because - (state, action, reward, state, action). The only difference
between SARSA and Qlearning is that SARSA takes the next action based on the current policy
while qlearning takes the action with maximum utility of next state.
Using the simplest gym environment for brevity: https://gym.openai.com/envs/FrozenLake-v0/
"""
def init_q(s, a, type="ones"):
"""
@param s the number of states
@param a the number of actions
@param type random, ones or zeros for the initialization
"""
if type == "ones":
return np.ones((s, a))
elif type == "random":
return np.random.random((s, a))
elif type == "zeros":
return np.zeros((s, a))
def epsilon_greedy(Q, epsilon, n_actions, s, train=False):
"""
@param Q Q values state x action -> value
@param epsilon for exploration
@param s number of states
@param train if true then no random actions selected
"""
if train or np.random.rand() < epsilon:
action = np.argmax(Q[s, :])
else:
action = np.random.randint(0, n_actions)
return action
def expected_sarsa(alpha, gamma, epsilon, episodes, max_steps, n_tests, render = False, test=False):
"""
@param alpha learning rate
@param gamma decay factor
@param epsilon for exploration
@param max_steps for max step in each episode
@param n_tests number of test episodes
"""
env = gym.make('Taxi-v2')
n_states, n_actions = env.observation_space.n, env.action_space.n
Q = init_q(n_states, n_actions, type="ones")
timestep_reward = []
for episode in range(episodes):
print(f"Episode: {episode}")
total_reward = 0
s = env.reset()
t = 0
done = False
while t < max_steps:
if render:
env.render()
t += 1
a = epsilon_greedy(Q, epsilon, n_actions, s)
s_, reward, done, info = env.step(a)
total_reward += reward
if done:
Q[s, a] += alpha * ( reward - Q[s, a] )
else:
expected_value = np.mean(Q[s_,:])
# print(Q[s,:], sum(Q[s,:]), len(Q[s,:]), expected_value)
Q[s, a] += alpha * (reward + (gamma * expected_value) - Q[s, a])
s = s_
if done:
if True:
print(f"This episode took {t} timesteps and reward {total_reward}")
timestep_reward.append(total_reward)
break
if render:
print(f"Here are the Q values:\n{Q}\nTesting now:")
if test:
test_agent(Q, env, n_tests, n_actions)
return timestep_reward
def test_agent(Q, env, n_tests, n_actions, delay=0.1):
for test in range(n_tests):
print(f"Test #{test}")
s = env.reset()
done = False
epsilon = 0
total_reward = 0
while True:
time.sleep(delay)
env.render()
a = epsilon_greedy(Q, epsilon, n_actions, s, train=True)
print(f"Chose action {a} for state {s}")
s, reward, done, info = env.step(a)
total_reward += reward
if done:
print(f"Episode reward: {total_reward}")
time.sleep(1)
break
if __name__ =="__main__":
alpha = 0.1
gamma = 0.9
epsilon = 0.9
episodes = 1000
max_steps = 2500
n_tests = 20
timestep_reward = expected_sarsa(alpha, gamma, epsilon,
episodes, max_steps, n_tests,
render=False, test=True
)
print(timestep_reward)
|
source: https://gist.github.com/TimeTraveller-San/5bd93710e118633e0793dc5d0b92b19a#file-expectedsarsa-py
比較
以下のパラメータで 3 つのアルゴリズムを比較しました
| lpha = 0.4
gamma = 0.999
epsilon = 0.9
episodes = 2000
max_steps = 2500 # (max number of time steps possible in a single episode)
|
ここでは、上記の 3 つの方策制御方法の比較 をプロットします。
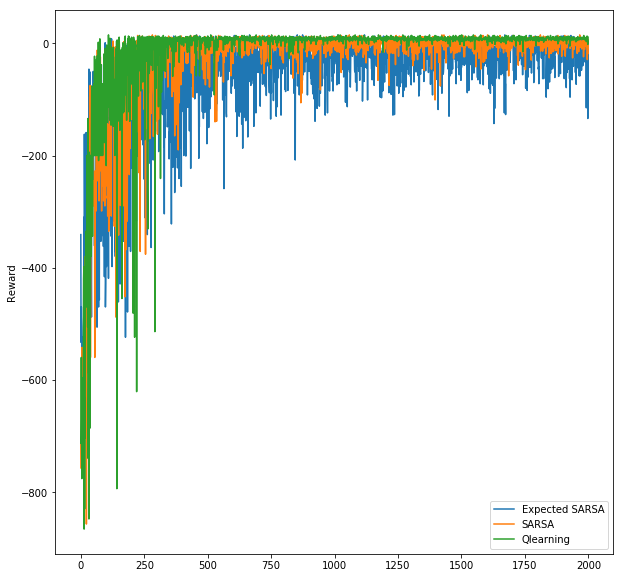
収束
以下のプロットが示すように、Q 学習 (緑) は SARSA(オレンジ) と 期待 SARSA(青) の両者より先に収束しました。
成績
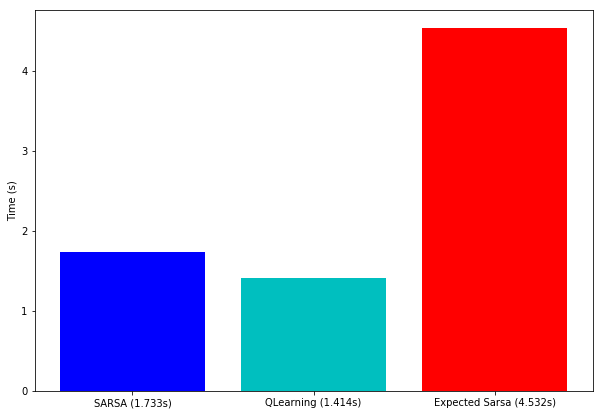
実装した 3 つのアルゴリズムでは、Q-学習 が最も良く、期待 SARSA が最も悪い性能のようです。
結語
時間差学習 は 最も重要な強化学習の概念です。 DQN や ダブルDQN のような、さらに派生したもの
は、AI の分野で有名な画期的な結果を達成しています。
Google の アルファ碁は、囲碁の世界チャンピオンを倒すために、CNN と DQN アルゴリズムを使用しました。