ディープラーニングの心理学的解釈 (心理学特講IIIA)¶
第 10 回 強化学習, 予測報酬誤差, ゲームAI, 経済学¶


AlphaGo の模式図,原著論文より
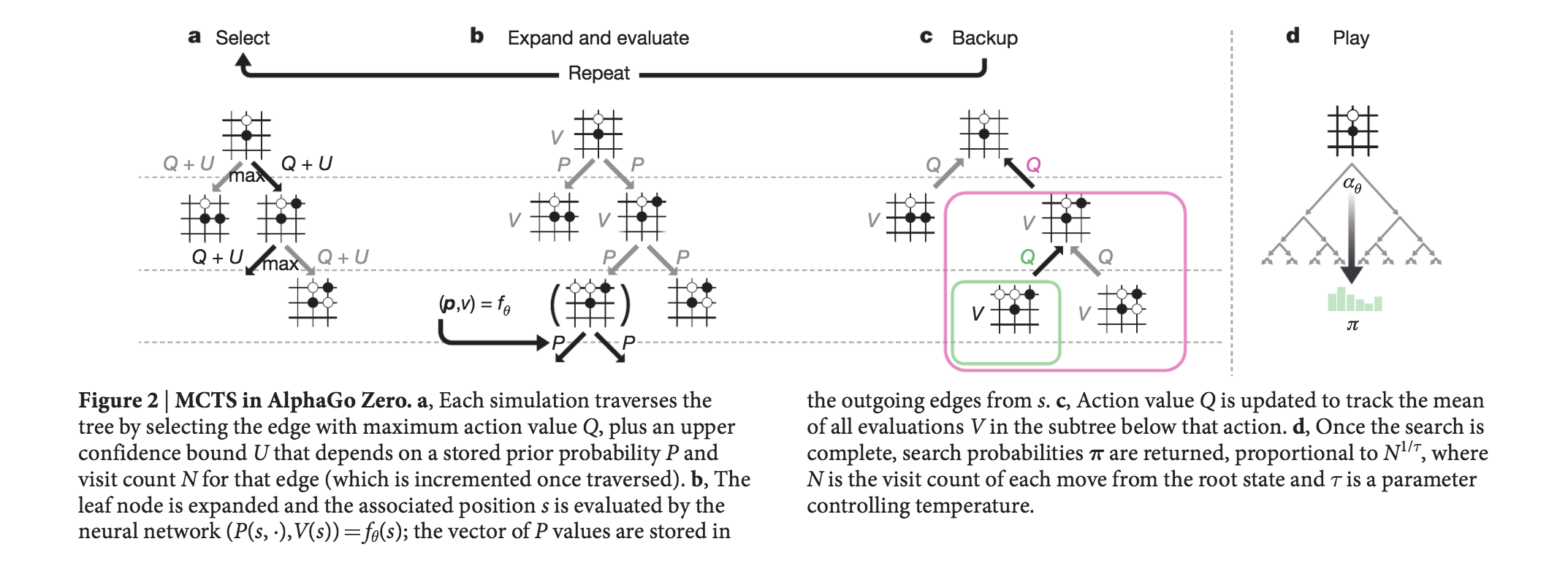
AlphaGoZero のセルフプレイ,原著論文より
実習ファイル¶
以下のデモは,OpenAI 提供の強化学習環境 gym を用いています。
Colaboratory 上で gym を 動作させるためには StarAI の開発したレンダリング環境 が必要です。
強化学習,条件付けの古典¶
- パブロフ (Ivan Petrovich Pavlov; 1849/Sep/14-1936/Feb/27)古典的条件づけ 1904 年ノーベル医学生理学賞
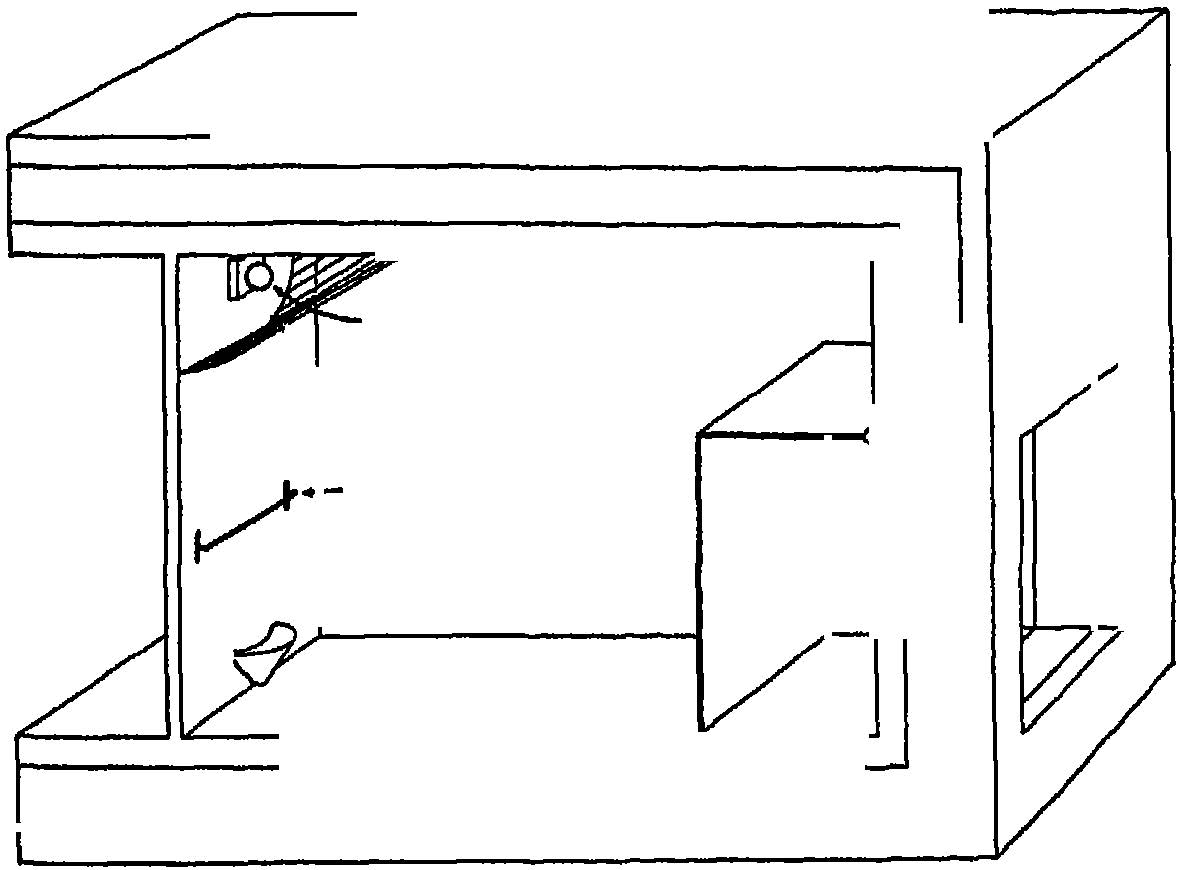
- スキナー (Burrhus Frederic Skinner; 1904/Mar/20-1990/Aug/18) 道具的条件付け, オペラント条件づけ,スキナー箱, Skinner(1938) Fig.1, page 39 より
- Sutton and Barto の強化学習 初版 1998年, 第2版 2018年, 初版は翻訳あり,第2版は pdf ファイルでダウンロード可能
{kind=link}
 Ian Pavlov
Ian Pavlov
 Burrhus Frederic Skinner
Burrhus Frederic Skinner
 Richard S. Sutton,
Richard S. Sutton,
 Andrew G. Barto
Andrew G. Barto
強化学習とは何か?¶

Sutton & Barto (2018) Fig. 3.2 を改変
強化学習という言葉は古い言葉ですが機械学習の文脈では, 環境とその環境におかれた動作主(エージェントと言ったり,ロボットシステムだったりします)が, 環境と相互作用しながらより良い行動を形成するためのモデルです。 動作主は,環境から受け取った現在の状態を分析して, 次にとるべき行動を選択します。このとき将来に渡って報酬が最大となるような行動を学習する手法の一つです。
2015 年には,Google傘下のデープマインドというスタートアップチームが開発した囲碁プログラムAlphaGoがプロ棋士のイ・セドル氏に勝利し話題になりました。 AlphaGo は強化学習を基本技術の一つとして用いています。
- 強化学習(1): 基礎
- 強化学習(2): エージェントと環境
- 強化学習(3): 目標と報酬
- 強化学習(4): マルコフ決定過程
- 強化学習(5): 価値反復,方策反復
- 強化学習(6):
-
エージェントと環境,マルコフ決定過程 MDP,POMDP,効用関数,ベルマン方程式,探索と利用のジレンマ,SARSA:
- 価値,方策,Q 学習,モデルベース対モデルフリー,アクター=クリティック:
-
深層 Q 学習:
-
ゲーム AI へ (AlphaGo,AlphaGoZero,OpenAI five):
- セルフプレイ:
- 最近の発展 A3C,Rainbow,RDT,World model:
複雑な状況をどう理解して解決するのか?¶
- 強化学習というニューラルネットワークモデルがあるわけではない
-
動的で複雑な環境に対処 強化学習 + DL 一般人工知能への礎
-
DQN ATARIのビデオゲーム, https://www.nature.com/articles/nature14236
- AlphaGo 囲碁, https://www.nature.com/articles/nature16961
- AlphaGoZero 囲碁, https://www.nature.com/articles/nature24270
Deep Q Network¶

DQNの模式図, 原著論文より
- Q 学習 Q learning に DNN を採用
- CNN が LeNet, @1998LeCun そうであったように,強化学習 RL も昔からの技術 @Sutton_and_Barto1998
- ではなぜ,今になって囲碁や自動運転に応用できるようになったのか?
- コンピュータの能力, データ規模,アルゴリズムの改良, エコシステム(ArXiv, Linux, Git, ROS, AMT, TensorFlow)
YouTube 上でのデモ動画¶
- ブロック崩し: https://www.youtube.com/watch?v=V1eYniJ0Rnk
- スペースインベーダー: https://www.youtube.com/watch?v=W2CAghUiofY
- DQN の動画 スペースインベーダー
- DQN の動画 ブロック崩し
DQN 結果¶
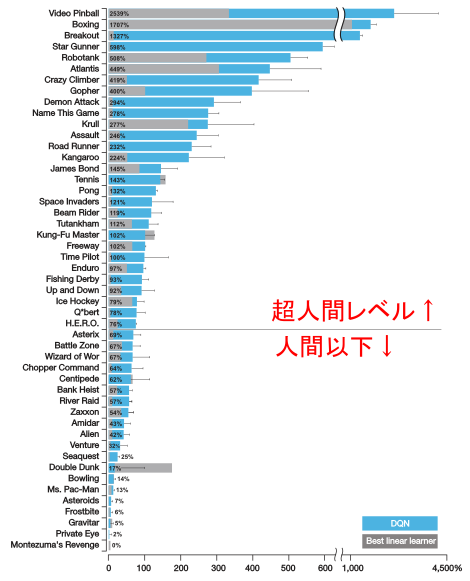
人間にはできて強化学習には難しいこと¶
- Montenzuma's Revenge の動画 https://www.youtube.com/watch?v=Klxxg9JM5tY
- Private Eys の動画 https://www.youtube.com/watch?v=OfyS-Wj1M78

すでに結果が古いのですが Rainbow の性能

すでに結果が古いのですが Rainbow の性能
- カルパシーのブログ http://karpathy.github.io/2016/05/31/rl/