ディープラーニングの心理学的解釈 (心理学特講IIIA)¶
実習¶
- 画像分割 detectron2 デモ
- CAM どこを見ているのか,どこを見て判断しているのか
- 転移学習
- Kaggle 上での Interactive demo for TL-GAN (transparent latent-space GAN)
先週の復習¶
- 意味的分割 (セマンティック・セグメンテーション)
- 物体(あるいは対象)分割 (オブジェクト・セグメンテーション)
- 実体分割 (インスタンス・セグメンテーション)
- バウディングボックス 関心領域の切り出し
詳しくは 先週の該当箇所 をご覧ください。
どこ (where) に 何 (what) があるのかを認識するための努力が 2014 年から長足の進歩を遂げました。 先週の課題ビデオにあった唐揚げロボットでは,意味的分割では対応不可能であることに注意
要点¶
- 外界の情報を受け取り,認識に至るために,哺乳類の視覚情報処理システムは少なくとも 2 つの経路を作り出して利用しているようである。
- 視覚系では,腹側経路で「何」が処理され,背側経路で「どこ」が処理されているらしい
- ニューラルネットワークでも,入力画像中の,どこに,何が,写っているのかを認識させるモデルが存在する。
- 認識性能の向上に伴い,この認識機能に立脚した発展が盛んである。
- 転移学習と生成についてとりあげる
2 経路仮説¶
- 腹側経路 ventral pathways ("what" 経路)
- 背側経路 dorsan pathways ("where" 経路)


Behnke (2003) より
同様の 2 経路による処理は 聴覚 (Romanski et al., 1999) や 触覚(Reed et al., 2005)でも発見されています。
二段階モデル¶
R-CNN ¶

Girshick (2013) より
Fast R-CNN と Faster R-CNN (2014)¶

Fast R-CNN
一段階モデル¶
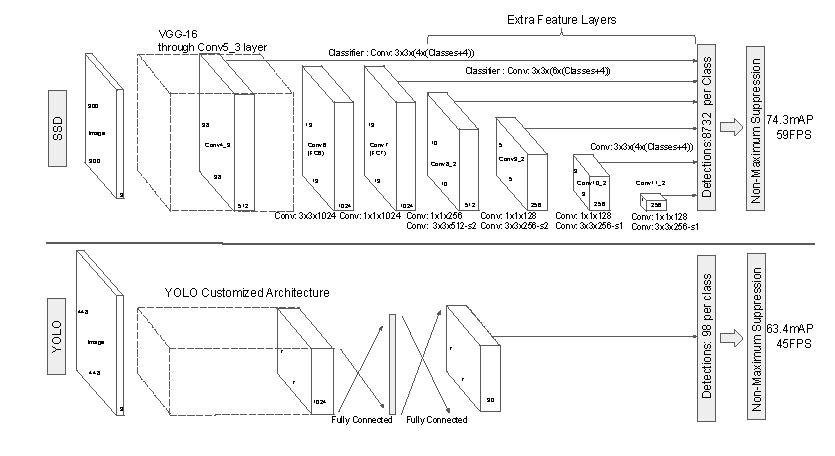
U-Net¶
画像分割の SOTA

Ronnenberger et. al (2015) Fig. 1 より

背骨 (バックボーン)ネットワーク と 周辺ネット¶



detectron2 の実習をしてみましょう。
Realtime Multi-Person 2D Human Pose Estimation using Part Affinity Fields, CVPR 2017 Oral
Paper: https://arxiv.org/pdf/1808.07371.pdf
Web site: https://carolineec.github.io/everybody_dance_now/
転移学習¶
転移学習 transfer learning は機械学習分野のみならず,ロボット工学や実応用の分野でも応用が考えられます。 シミュレーションと現実との間隙をどのように埋めるのかという大きな問題に関連します。 一方で,転移学習と ファインチューニング や 領域適応* domain adaptation の区別がなされています。
転移学習とは 課題 A を用いて訓練したモデルに対して,別の課題 B に適用することを言います。 DNN では転移学習は頻用されます。 イメージネットで画像分類を学習したネットワークに対して,例えば顔認識を学習させるような場合です。
PyTorch のチュートリアルなどでは,学習済のネットワークに対して,最終直下層を入れ替えて別の課題を訓練することを転移学習と呼びます。 このとき,最終直下層と出力層との結合を学習させ,その他の下位層の結合は固定し,訓練しません。 一方で,下位層まで含めて全結合を訓練させる場合をファインチューニングと呼び,区別しています。
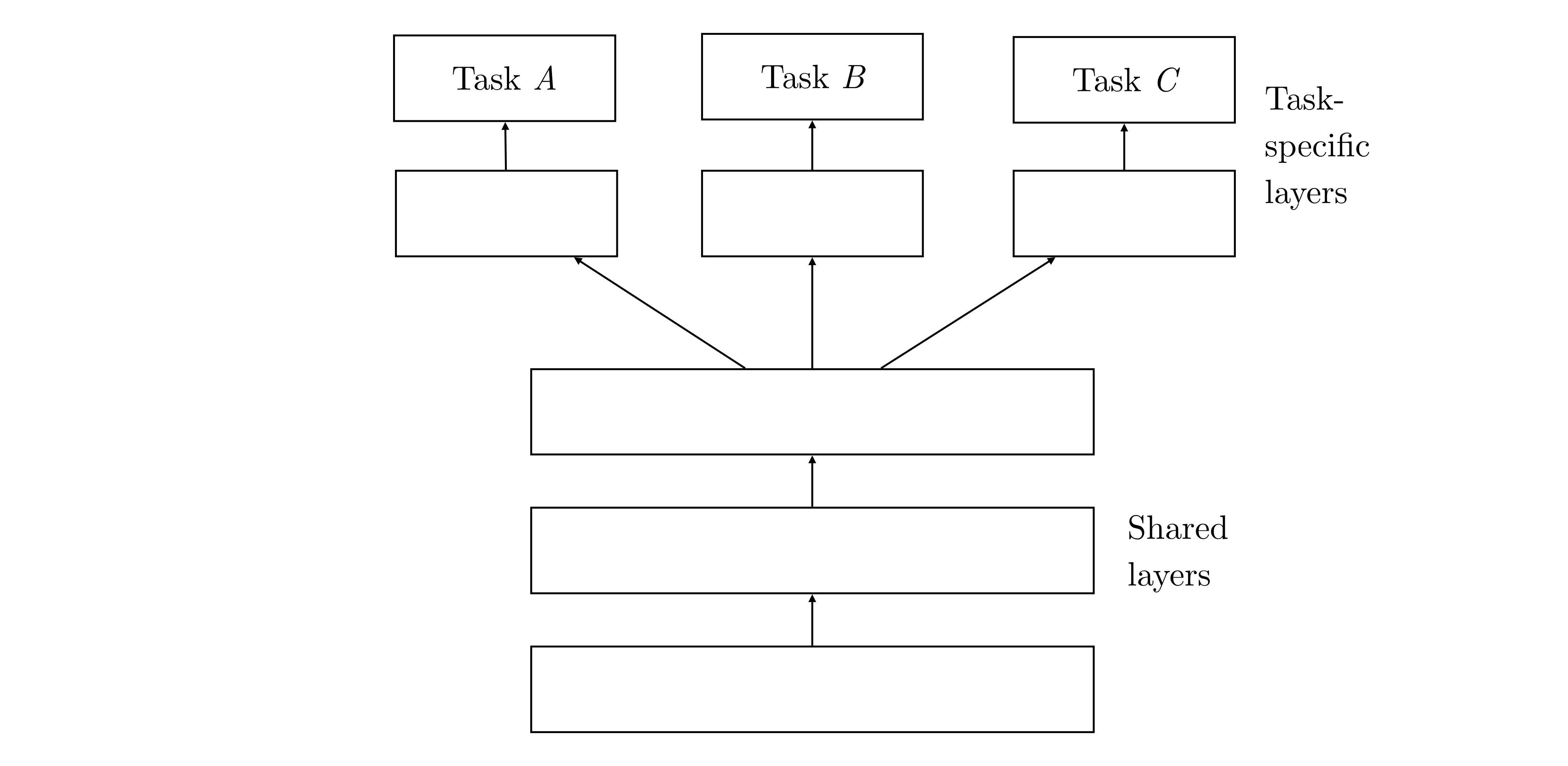
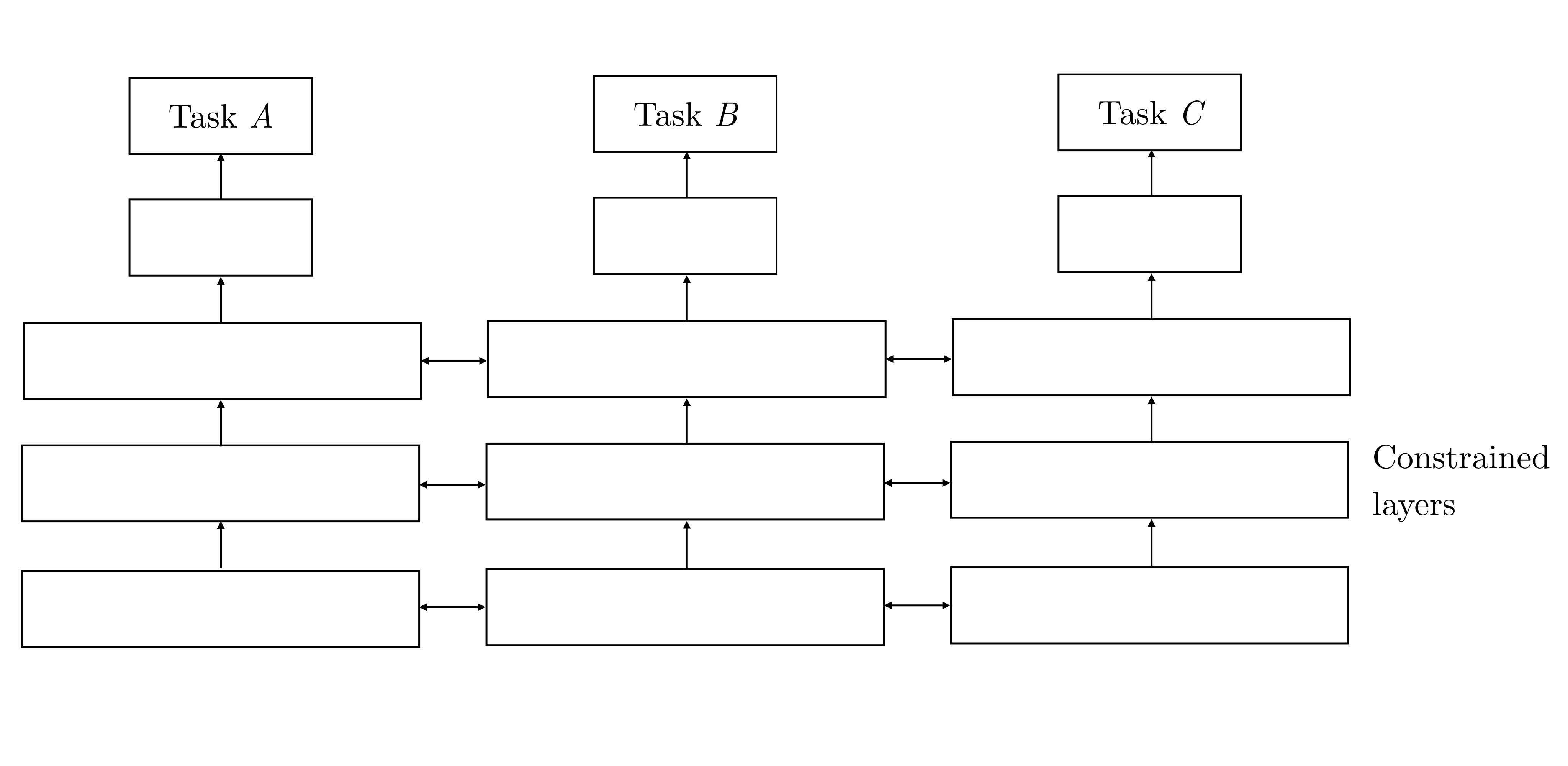
左: ハードパラメータ共有: 転移学習, 右: ソフトパラメータ共有: ファインチューニング
生成モデル¶
認識の反対の操作をすれば,生成が可能です。生成敵対ネットワーク Generative Adversarial Networks: GAN になります。
GAN では 2 つのニューラルネットワークが用いられ,識別器 descriminator と 生成器 generator と呼びます(Goodfellow,2014)。 識別器も生成器も多層ニューラルネットワークです。 通常の画像分類課題では,最上位層において推論,すなわち入力画像が何であるかを計算するためにソフトマックスる関数などが用いられます。 これに対して GAN の識別器では,0 か 1 かの出力をします。入力画像が通常の画像であれば 1 を,生成器によって生成 された画像であれあば 0 を出力します。 生成器は,識別器の最終直下層で得られたような画像表現に雑音を加えた値から画像を生成します。 生成器は,識別器が入力データから画像を推論するのと逆方法に推論から画像を生成します。 すなわち GAN は入力が実在するか,偽造品,すなわちフェイクかを見破る訓練がなされることになります。
このようにして,生成器は識別器の学習成果であるデータの内部表現を模倣し,生成器を欺こうします。 このようにして識別器と生成器との間で ゲーム理論でいう ナッシュ均衡 Nash's equilibrium が成り立ちます (Heusel, 2017)。 GAN の模式的な流れを下図 に示しました。

画像変換¶




サイクル GAN¶

サイクル GAN による領域変換¶




まんがの画風変換¶
 ``CartoonGAN: Generative Adversarial Networks for Photo Cartoonization'' CVPR 2018 (Conference on Computer Vision and Pattern Recognition)
``CartoonGAN: Generative Adversarial Networks for Photo Cartoonization'' CVPR 2018 (Conference on Computer Vision and Pattern Recognition)


左: 君の名は。右: 風の谷のナウシカ,より